
TL;DR
The Model Context Protocol (MCP) is an open-source standard that simplifies integrating AI assistants with tools (the things AI assistants use to perform actions) and data sources (the locations AI assistants go to for information). With so much momentum behind it, MCP is poised to become the standard for AI-to-tool interactions; paving the way for more intelligent and responsive AI applications.
This article expands on these capabilities with an concrete example of a food ordering AI assistant.
– Model Context is the surrounding information — like conversation history, user preferences, goals, and external data — that AI models use to generate more relevant and coherent responses.
– Model Context Protocol (MCP) is a standard that helps AI agents efficiently interact with data sources and external tools without needing a custom integration for every single one.
– Without MCP, building AI agents requires tedious, high-maintenance integrations. MCP streamlines this by creating reusable connections across apps and data.
– Challenges remain: MCP still has issues with authentication, security (blind trust risks), cost control (token usage), and protecting sensitive data.
MCP isn’t perfect yet, but it’s a big step toward more powerful, context-aware AI systems that are easier and faster to build.
- TL;DR
- What is Model Context?
- How Does MCP Help? A Real-World Example
- Are You Saying Framework Tools Are Bad?
- In Conclusion: Do Not Ignore MCP
What is Model Context?
Before nerding out on the protocol itself, let’s understand what context is and how it applies to different AI models with different modalities (ex. language models, vision models, audio models, or models that support more than one of these modalities).
According to Merriam-Webster, context is “the parts of a discourse that surround a word or passage and can throw light on its meaning” or “the interrelated conditions in which something exists or occurs.”
In the world of AI, this translates to the surrounding information—textual, visual, auditory, or situational—that informs and shapes the model’s response. Each model type uses context in different ways depending on the modality and the problem being solved.
Model context is the information a language model uses to understand the user’s intentions and provide relevant, coherent responses. This includes:
– Conversation History: Previous prompts and responses.
– User Preferences: Style, tone, depth of answers.
– Task Goals: Long-term objectives and/or short-term instructions.
– External Data Repositories: Files, websites, document libraries, or other repositories.
How Does MCP Help? A Real-World Example
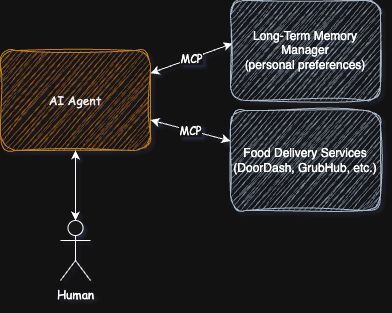
The Model Context Protocol (MCP) unifies how AI systems perform actions and interacts with data repositories.
Let’s walk through a real-world example so you can understand where exactly MCP fits in. First, I’ll walk through the process without AI, then I’ll talk through the process with an AI agent.
Situation and Background
For this example, let’s assume your planning dinner for you and a friend. It’s been a while since you’ve eaten at your favorite Indian restaurant. Chicken tikka, rice, and naan bread are your go-to dishes there, but you know that won’t be enough for the both of you, so you’ll need to figure out another dish when you get there…on second thought, you want delivery and, being a digital native, you’ll place your order online (DoorDash, GrubHub, UberEats, etc.) to arrive by 6:30p.
No AI Agent – A Familiar Flow
Without an AI agent, you’ll go through a process similar to below:
1. Log into your preferred food delivery service
2. Search for the restaurant.
3. Add your favorite items to the cart
4. Examine comments and reviews about the restuarant to figure out other popular dishes
5. Select a dish with positive reviews (samosas!)
6. Set time for delivery and complete check-out
Many things happen behind the scenes, we won’t focus on how those processes may or many not leverage AI, and food arrives before you get “hangry”.
AI Agent Doing the Work
If you had a full-blown agent, something similar to the above would happen based on a single command:
“Order food from my favorite Indian restuarant. Get my usual items and surprise me with a popular dish. I need the food delivered to my house by 6:30p”
The agent will then perform roughly the following sequence:
1. Think about the set of actions requried to fulfilled the request
2. Determine it needs to more context (ex. what is your favorite Indian resturant? what do you typically order there?)
3. (data) Examine chat history and personal preferences to determine your favorite restuarant: Tandoori Oven
4. (data) Examine chat history and personal preferences to determine your home address
5. (data) Examine chat history and personal preferences to determine your preferred food delivery service
6. (data) Examine your order history to determine what you typically order: chicken tikka, rice, garlic naan
7. (data) Examine reviews of the restuarant to see what is popular: samosas
8. (tools) Add items to cart
9. (human in the looop) Confirm the order before placing it
10. (tools) Checkout and set delivery to your house by 6:30p
I intentionally tagged the steps where the agent is accessing data and using tools; it’s these steps that can leverage MCP…let’s see how.
How MCP Helps You Build Agents More Effeciently
What if you were tasked with making the above agent? How would you build it?
It’s very possible to create the above agent without using MCP at all. Many of the popular agentic frameworks include an inventory of built-in “tools” (or sometimes called “functions” or “skills”) that improve memory management and allow models to interact with external services.
* LangChain/LangGraph
* Autogen
* Crew.ai
* OpenAI Swarm
* Hugging Face Transformers Agents
* etc.
At time of this writing, none of those frameworks provide the capability to interact with any of the food delivery services (DoorDash, GrubHub, UberEats, etc.)…sure you could design things to interact with those sites using a browser (ex. BrowserUse) but the results won’t be as concise and you may want (and it’s a lot more testing and debugging).
What about building a custom tool for the framework?
You could examine the APIs these delivery services provide and create a custom tool (you could even use AI itself to build this tool)…but don’t underestimate the ongoing testing and maintenance required to accomodate changes to the APIs (which will certainly change over time).
Avoiding the MxN Integration Problem
The above quandry about creating a custom tool is a major motive for MCP’s introduction.
“M” AI applications need to connect to “N” data sources, leading to an exponential increase in custom integrations (MxN).
However, if there was an MCP server that knows how to manage your personal preferences and one that interacts with the food delivery services, it sure would simplify the process…and reduce maintenance.
Are You Saying Framework Tools Are Bad?
No, built-in tools will always have a place. They can be tuned for speed and token reduction (less back and forth chatter). But, as MCP implementations become more prevalent and mainstream (not just side-projects but actual vendor supported services) you’ll see a shift from framework based tools towards MCP based designs.
That Settles It, MCP Will Take on the World
Not yet, there are still some shortcomings that the MCP specification needs to work through.
Authentication and Authorization (authn/authz)
In the above example, I glossed over the fact that the AI agent needs to interact with the food delivery services as you…the person with the account and payment information. The initial revision of the MCP spec didn’t address this. Now that they have, there are still some shortcomings to the design (which Christian Posta dives into details on)
Blind Trust
Many of the MCP server implementations are susepetible to command injection vulnerabilities. If you are only consuming these servers (not creating them) it’s not a major concern right? Until you find yourself running those servers locally (on your laptop or cloud machines) and you see the agent is taking harmful actions (whether intentionally or just because it’s spiraling down the wrong course of thinking).
Lack of Cost Controls
The quality of MCP servers vary and, unlike custom tools, it’s easy for the server developer to return large amounts of text in responses. During the course of a dialog between the model and the server, the history of the text can add up (resulting in large token consumptions and larger costs for agent execution)
Unwitting Data Exposure
Similar to the Blind Trust problem, and related to the authn/authz shortcomings, an MCP server implementation may return data that you (and the agent acting on your behalf) shouldn’t have access too.
In Conclusion: Do Not Ignore MCP
Model Context Protocol (MCP) isn’t a magic wand that instantly solves every challenge in building smarter, more capable agents — but it is a major leap forward. By standardizing how models interact with data and tools, MCP drastically reduces the complexity of integrations and helps avoid the dreaded MxN problem.
As MCP matures, expect to see faster development cycles, better interoperability between AI systems, and a shift toward more modular, maintainable designs. But, as we explored, MCP isn’t without its growing pains: security concerns, cost management, and responsible data access will remain critical issues for practitioners and vendors to address.
The bottom line? MCP is setting the foundation for a new era of AI agents — one where context is richer, actions are more reliable, and developers spend more time building value and less time gluing systems together. Stay curious, stay cautious, and get ready: the next wave of AI innovation is just getting started.
